
Überwachtes- vs. Unüberwachtes Lernen – Was ist das eigentlich?
Haben Sie sich schon mal gefragt, ob es einen Zusammenhang zwischen dem Wetter und Ihren Umsatzzahlen gibt oder wie sich Ihr Umsatz in den nächsten Monaten entwickeln wird? Falls ja, haben Sie sich vermutlich häufiger eine „Black Box“ für diese und ähnliche Probleme gewünscht. Sie geben Ihr Problem als Input hinein und auf der anderen Seite kommt auf magische Weise die Lösung heraus.
Aber machen Algorithmen im Machine Learning nicht genau das? Finden wir es heraus.
Hierzu ist es erst einmal wichtig, zu verstehen, was ein Algorithmus eigentlich ist. Einfach gesagt ist ein Algorithmus eine Vorgehensweise, um ein Problem zu lösen. Bei der Entwicklung von Chatbots stehen wir zum Beispiel vor dem Problem, dass wir wissen müssen, welche Fragen Nutzer haben. Dafür nutzen wir bei Onlim einen Algorithmus zur Themenerkennung. Mithilfe dieses Algorithmus versuchen wir zu verstehen, welche Themen die Nutzer beschäftigen und welche Fragen besonders häufig gestellt werden.
Was ist der Unterschied zwischen Supervised und Unsupervised Learning?
Nun ist es allerdings so, dass dieser Algorithmus stetig verbessert und trainiert werden muss. Denn egal wie gut man die Nutzer seines Chatbots und dessen Probleme kennt: Es können immer wieder neue Themen oder Rückfragen auftauchen, an die Sie niemals gedacht hätten.
Die Trainingsarten für Algorithmen lassen sich in zwei Hauptkategorien aufteilen: Unsupervised Learning (Unüberwachtes Lernen) und Supervised Learning (überwachtes Lernen). Diese unterscheiden sich vor allem im verwendeten Trainingsdatensatz und den Anwendungsmöglichkeiten.
Datensatz
Dem Algorithmus wird ein Beispieldatensatz vorgegeben. Dieser enthält Daten, die bereits in bestimmte Kategorien (Cluster) eingeteilt sind (labeled data).
Anwendungsfälle
Gut geeignet, um Klassifizierungen vorzunehmen, d. h. die Daten anhand von vorgegebenen Kategorien einzuteilen.
Ebenfalls gut geeignet zur Regressionsanalyse, um zum Beispiel Vorhersagen zur Häufigkeit der gestellten Fragen zu machen.
Datensatz
Dem Algorithmus werden Daten vorgeben, die über keine vorherige Einteilung verfügen (unlabeled data).
Anwendungsfälle
Gut geeignet zum Clustering, d. h. um Muster in Daten zu erkennen und diese anhand ähnlicher Muster zu kategorisieren.
Auch geeignet für die Assoziationsanalyse, um zu erkennen, welche Zusammenhänge es unter den Daten gibt.
Unüberwachtes Lernen ist nicht perfekt
Auf den ersten Blick scheint der Unsupervised-Learning-Ansatz die ersehnte Black Box zu sein, durch die man automatisch Muster oder Zusammenhänge in den Daten erkennt, ohne über diese im Vorfeld Bescheid zu wissen. Das kann zum Beispiel wie in unserer anfänglichen Fragestellung ein Zusammenhang von Wetter und Umsatz sein.
In der Theorie kann ein Unsupervised Learning Algorithmus solche Zusammenhänge finden. In der Realität ist es jedoch so, dass der Unsupervised-Learning-Ansatz zwar für einige Anwendungsfälle gut funktioniert, es aber oft Ausreißer und Ungenauigkeiten gibt. Es kann zum Beispiel sein, dass die Einteilung beim Clustering für einige Kategorien überhaupt keinen Sinn ergibt oder zusätzliche Informationen zu den Datenquellen benötigt werden.
Der Twitter-Account „City Describer“ zeigt zahlreiche Beispiele solch fehlerhafter Einteilungen. Auf diesem Account findet man Fotos von Städten, die mithilfe der Computer Vision AI von Microsoft beschrieben wurden. Leider nicht immer mit Erfolg. Beispielsweise wird der Central Park mit einer Verkehrsampel an einem Baum verwechselt oder der Vatikan wird für einen Tisch mit Essen gehalten.

City Describer
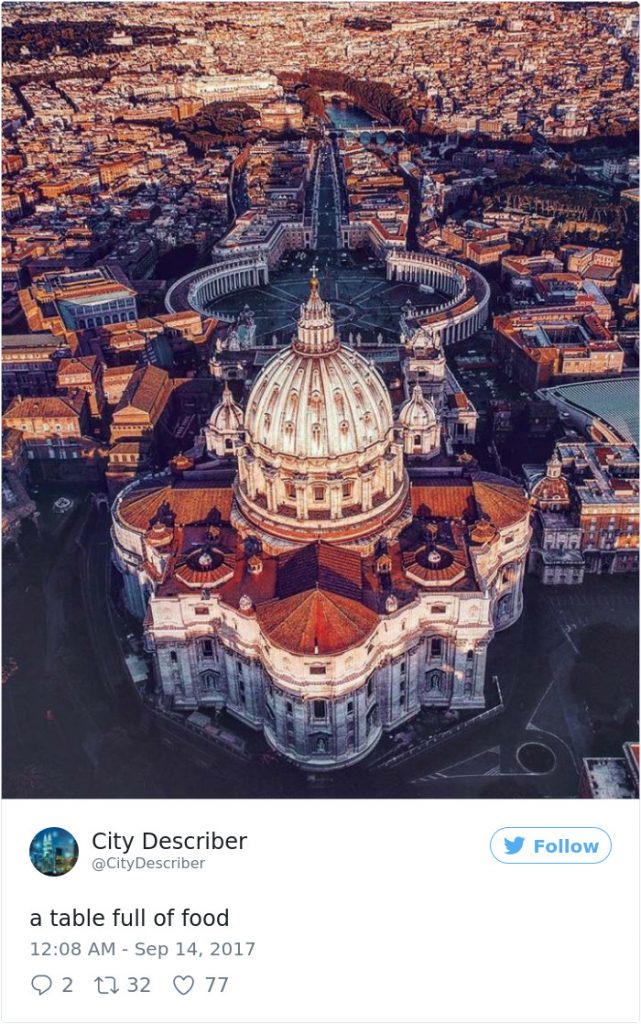
City Describer
Die richtige Mischung macht’s
Da die Einteilung mithilfe eines Unsupervised-Learning-Ansatzes nicht immer verlässlich funktioniert, ist eine Kombination aus verschiedenen Supervised- und Unsupervised-Learning-Ansätzen häufig eine gute Wahl. Bei Onlim nutzen wir zum Beispiel eine Kombination der beiden Ansätze zum Entdecken zusätzlicher Suchbegriffe.
Nehmen wir einmal an, dass Sie einen Bot entwickelt haben, der Nutzern Fragen zu Events beantwortet. Der Bot ist in der Lage Fragen zu beantworten, wenn der Nutzer nach Events an einem bestimmten Ort oder Datum fragt. Diesen Bot möchten Sie weiter optimieren. Hierzu können Sie einen Unsupervised Learning Ansatz nutzen, mit dem Sie weitere Themengebiete identifizieren. Dabei finden Sie heraus, dass die Nutzer nicht nur für Events an einem bestimmten Ort oder Datum interessieren, sondern auch für Events unterschiedlicher Richtungen, wie Sport oder Musik.
Diese Erkenntnis können Sie dazu verwenden, um einen Supervised Learning Algorithmus zu trainieren, der die Nutzernachrichten in die Eventkategorien einsortiert.
Zusätzlich arbeiten wir bei Onlim daran, anhand von Nutzernachrichten neue Themengebiete zu erkennen. Stellen Sie sich folgendes Szenario vor: Sie haben einen Bot für ein Ski Resort gebaut, der Fragen rund um den Aufenthalt beantworten kann. Trotz bester Umsetzung, kann es immer vorkommen, dass Probleme und Fragen auftauchen, für die der Bot bisher nicht trainiert wurde. So kann es zum Beispiel sein, dass sich im Skigebiet plötzlich die Witterungsbedingungen verschlechtern und dadurch vermehrt Fragen zur Nutzung von Schneeketten, Winterreifen oder der aktuellen Schneehöhe auftauchen. Ein Unsupervised Learning Ansatz kann helfen, auf diese Themengebiete aufmerksam zu werden. Anschließend können wir neue Cluster definieren, sie mithilfe eines Supervised Learning Ansatzes verfeinern und für das weitere Training des Bots nutzen.
Die Beispiele verdeutlichen, dass die Bezeichnung „Unsupervised“ irreführend ist. Das Prüfen und Anpassen der Ergebnisse sowie eine Kombination unterschiedlicher Algorithmen ist der Normalfall. Eine interessante Sichtweise auf dieses Thema hat auch das Paper „Is ‚Unsupervised Learning‘ a Misconceived Term?“. Dieses schlägt vor, die Begriffe eher in „Internally“ und „Externally Supervised“ umzubenennen.
Die Zukunft von Unsupervised Learning
Nur weil es in der Realität noch kein „wirkliches“ Unsupervised Learning gibt, bedeutet dies allerdings nicht, dass an diesem Thema nicht gearbeitet wird. So beschreibt Pedro Domingos in seinem Buch „The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World“ wie Forschungseinrichtungen mit Hochdruck daran arbeiten, den „ultimativen Algorithmus“ zu entwickeln, der aus einer Kombination von Unsupervised und Supervised Learning Algorithmen besteht
Wie lange es dauert, bis es tatsächlich eine Art Black Box gibt, ist fraglich. Bis dahin lassen sich allerdings mit der Kombination verschiedener Trainingsansätze bereits beeindruckende Ergebnisse erzielen.
Wenn Sie sich interessieren, für welche weiteren Bereiche wir unüberwachtes Lernen verwenden und welche Vorteile das für Ihren Chatbot hat, vereinbaren Sie ein kostenloses Beratungsgespräch mit einem unserer Chatbot-Experten.
Der ultimative Chatbot-Leitfaden
Das erwartet Sie im E-Book:
Im E-Book “Der ultimative Chatbot-Leitfaden” erfahren Sie, welche Chancen Chatbots Unternehmen für interne sowie externe Anwendungsfälle bieten und erhalten wichtige Tipps zur Implementierung.

Was sind Large Language Models (LLMs)?
März 18th, 2024|

Was sind Chatbots und wie funktionieren sie?
November 23rd, 2023|
